Data Driven Age Post-processor¶
Purpose¶
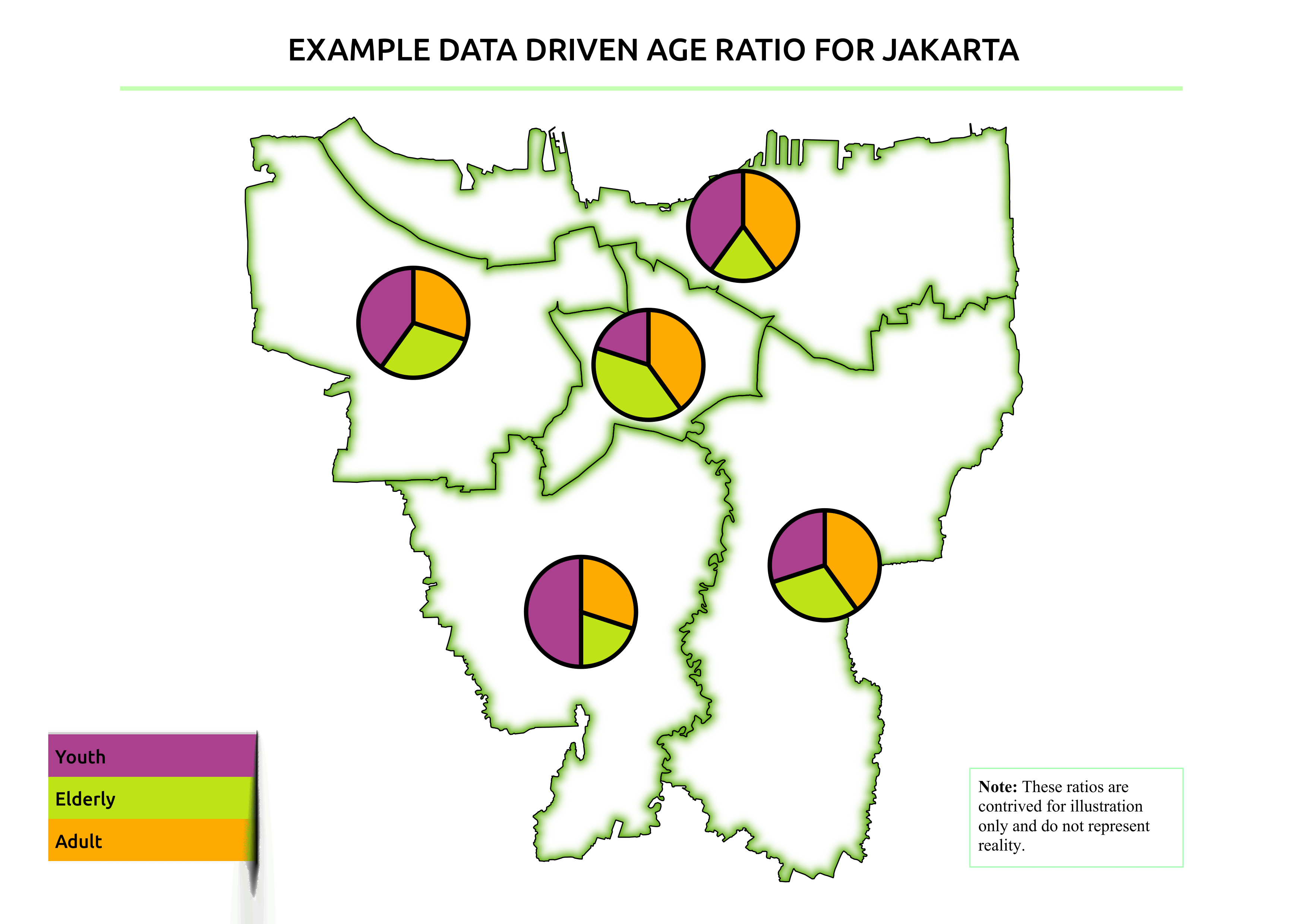
Data driven age processing is carried out during aggregation to determine how many people are affected by a hazard according to their age distribution (youth, adult, elderly). This feature is similar to the gender post-processor. With data driven age, a custom age distribution ratio is used. This is specified either in the data attributes of the aggregation polygons, or by setting a global ratio for the whole aggregator vector layer using the keywords editor or keywords wizard.
This feature is used to give more specific information by giving the number of affected youth, adult and elderly in an area such as within the boundaries of a village. This can help better identify what areas should be priorities during rescue operations and to give more attention to the vulnerable population (e.g. elderly) and their needs.
Guidelines¶
Data needed¶
The aggregator vector layer should contain percentage of age distribution in the attribute table.
YOUTH |
ADULT |
ELDERLY |
|---|---|---|
0.30 |
0.40 |
0.30 |
0.25 |
0.65 |
0.10 |
Category¶
Ratio attributes or Ratio defaults should be populated up.
Key |
Allowed Values |
|---|---|
youth ratio attribute / youth ratio default |
youth |
adult ratio attribute / adult ratio default |
adult |
elderly ratio attribute / elderly ratio default |
elderly/elder |
Age postprocessing options can be specified either using ratio attributes or ratio defaults.
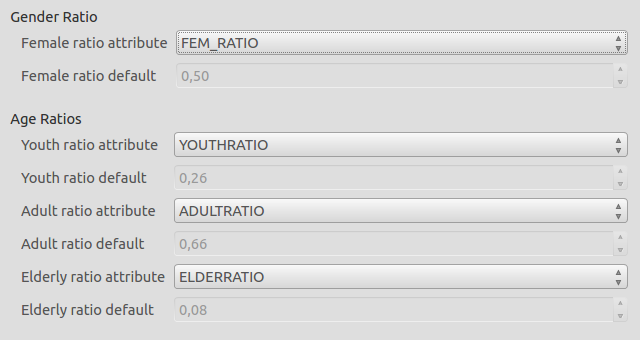
1. Ratio Attributes: In this mode, data used for postprocessing is from the attributes of the aggregation layer itself. Consider the example below where each aggregation area has an attribute indicating the ratios of age or gender.
In the keywords editor you can refer to these attributes and the age and gender ratios will be extrapolated based on the defined values.
2. Ratio Defaults: In this mode, the default values will be used. In this case you may not know per-area what the age and gender breakdowns are but rather apply the ratios globally (to all aggregation areas).
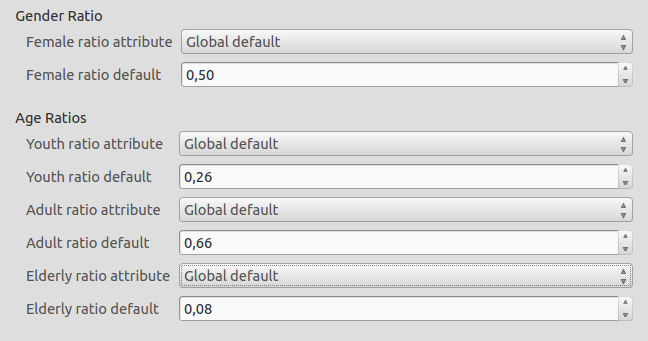
A similar user interface is provided in the keywords wizard user interface.